
One of the key directions for digital transformation applied in various industries including travel is Data Analytics. Hospitality is not an exceptional sector nowadays. Typically, the nature of the hotel industry is to generate and operate voluminous data. From inventory to distribution channels, housekeeping records to customer behavior data. There is so much to manage and maintain. Furthermore, as the business grows, these tasks become cumbersome in terms of doing analysis and it is hard to track everything by using several spreadsheets.
Here comes the unprecedented innovation existing in the world of digital transformation of the hospitality sector. Business data intelligence exists to solve the problems of data capturing and its analysis. It is a range of tools designed to collect data from multiple sources and transform the raw information into the meaningful form of numbers, analysis, reports, and much more.
The article today is about some of the key specific components that can be applied using Business data intelligence in the hotel industry. We shall find out various ways in which we can yield the productivity of the hotel business by harnessing the power of AI and business data analytic tools.
Business Intelligence in Hotels: Data sources and Components
The critical components of all the BI systems and the data sources are discussed below and can be used across all the hotels. A business data intelligence system extracts the data from various sources, transforms it, and collects it in a common repository. The repository is queried to present data that is meaningful in form of charts and diagrams for human interpretation.
The data source of a hotel can be internal or external and contains valuable data about your business, customer information, metrics, etc. Companies generally use Property Management System and its modules like Revenue management system and channel management as the key data source for hospitality business.
The above diagram is the PMS structure with various modules. Each module serve as a data source even if it is website analytics, housekeeping, or supply management system. Across the entire industry, there are various types of PMS structures that can be found. Some hospitality businesses need a separate module for yield management and some do not. Different hotels store a different number of components and data. This determines the general data structure that is adopted inside any organization.
The hotel business involves an ample number of activities and hence the data structure differs from hotel to hotel. Regarding business data intelligence, there are various challenges in establishing the right data for analysis. Let us find out more about how we can manage the entire data with great productivity and efficiency.
Building Modern Data Analytics Platform on AWS
AWS delivers an integrated suite of services that provide everything needed to quickly and easily build and manage a data lake for analytics. AWS-powered data lakes can handle the scale, agility, and flexibility required to combine different data and analytics approaches to gain deeper insights, in ways that traditional data silos and data warehouses cannot.
What is Data Lakes?
To build your data lakes and analytics solution, AWS provides the most comprehensive set of services to move, store, and analyze your data.
Data Movement: Extracting data from different sources like (SFTP, FTP, AWS S3 Bucket, Dropbox, Google Drive, or On-Premise HDD) and different types of data structures like (XML, CSV, PDF, DOC, EXCEL, JSON, or TEXT).
The first step to building data lakes on AWS is to move data to the cloud. The physical limitations of bandwidth and transfer speeds restrict the ability to move data without major disruption, high costs, and time. To make data transfer easy and flexible, AWS provides the widest range of options to transfer data to the cloud. To build ETL jobs and ML Transforms for your data lake via SSIS or AWS Glue Services.
Once data is ready for the cloud, AWS makes it easy to store data in any format, securely, and at a massive scale with Amazon S3, AWS Redshift, or Amazon Glacier. To make it easy for end-users to discover the relevant data to use in their analysis, AWS Glue automatically creates a single catalog that is searchable, and iqueryable by users.
Analytics:
Analyze your data with the broadest selection of analytics services or algorithms. With AWS you get the broadest and most cost-effective set of analytic services running on a data lake. Each analytic service is built with the purpose for a wide range of analytics use cases such as warehousing, real-time analytics, and much more.
Machine Learning: Predict the Future outcomes and provide rapid response.
For predictive analytics use cases, AWS provides a broad set of machine learning services, and tools that run on your data lake on AWS. For machine learning, it is recommended to use the below AWS services
- Deep learning AMIs for Frameworks and Interfaces
- Sagemaker for Platform Services
Hotel Industry Revenue Management System With Combined Power of AI and Data Science
These new-age arrangements additionally take care of a few problems faced during legacy RM systems such as real-time data processing, accuracy, autonomy, and integrity.
It’s significant for hotels to find data about travelers. So, they can customize the experience to meet the specific needs of the individual. Artificial intelligence can be an important instrument in this. Eventually, the challenge of gathering and investigating information will be rearranged by innovation that is sufficiently brilliant to settle on key decisions about guests’ behavior and characteristics.
With the power of AI and data analytics, you can perform an excellent hotel revenue management system. Flooded with the list of duties, the hotel management system should be collaborated with all hotel departments, in particular, marketing and sales. The core focus of an advantage of the system incorporates stock management, marketing, forecasting, pricing, and distribution channel management. Moreover, an AI-powered revenue management system can help with tasks like data analysis and, with data gathering, the RM can adequately learn and adjust to client interactions.
Applying Yield in Hospitality Industry
Yield Management allows you to select the optimal rate with the highest probability of selling based on the arrival date, length of stay and Type of Room guest was selected.
With the Yield Management, you can distribute the best available rate and other controls to various distribution channels (like Corporates or Tour agent) eliminating the need to manually enter the data. With the Yield Management Group Pricing strategy you have the option to determine the group’s entire value which factors in rooms, costs and commissions, conferencing and banqueting, ancillary spend and profits as well as the value of any business being displaced before you book.
The Yield Management provides hoteliers with an easy method to assess your hotel’s performance on a daily, weekly, monthly, and annual basis against your financial goals. More or less Yield Management provides a clear view to the information most important to you, and monthly graphical views of Estimated Room Revenue, Occupancy, Revenue per Available Room per Revenue and Average Daily Rate along with Alerts, Special Events and My Links are delivered in an easily navigated way.
Process includes following 5 stages:
-
Data Collection
Historical Row data collection
Gathering already processed data
Live data
Factors and Attribute definition by Manager - Organizing the Data
- Classification of Data
-
Presentation
Diagrams
Graphs - Analysis & Interpretation
The yield management is appropriate under one or more of the following scenarios, during conditions of fixed capacity (number of rooms), when the inventory is perishable (consumable – sold the rooms for every day), when the consuming market can be subdivided into demand segments, when peaks and low exists in the demand curve, and when advanced selling occurs (reserving the rooms in future).
Performance Driven Via Multi Tenant Database Architecture
Cloud computing has enabled businesses to infinitely scale services based on demand while reducing the total cost of ownership. Software as a ser-vice (SaaS) vendors capitalized on the scalable nature of Infrastructure as a Service (IaaS) to deploy applications without having the need for heavy upfront capital investment.
While you create a multi-tenant SaaS application for your hospitality platform, you must be careful during choosing the tenancy model that fits the best as per the needs of your application. A tenancy model determines how each tenant’s data is mapped to storage. There are various tenancy models such as single-tenancy, multi-tenancy, and hybrid tenancy models.
Below are the enumerated ways of choosing an appropriate tenancy model so that you can understand and decide upon which models suit best for your business.
Scalability:
- Number of tenants.
- Storage per-tenant.
- Storage in aggregate.
- Workload.
Tenant isolation:
- Data isolation and performance (whether one tenant’s workload impacts others).
Per-tenant cost:
- Database costs
Development complexity:
- Changes to schema.
- Changes to queries (required by the pattern).
Operational complexity:
- Monitoring and managing performance.
- Schema management.
- Restoring a tenant.
- Disaster recovery.
Customizability:
- Ease of supporting schema customizations that are either tenant-specific or tenant class-specific.
Multi-tenant app with database-per-tenant
This next pattern uses a multi-tenant application with many databases, all being single-tenant databases. A new database is provisioned for each new tenant. The application tier is scaled up vertically by adding more resources per node. Or the app is scaled out horizontally by adding more nodes. The scaling is based on workload, and is independent of the number or scale of the individual databases.
Multi-tenant app with multi-tenant databases
Another available pattern is to store many tenants in a multi-tenant database. The application instance can have any number of multi-tenant databases. The schema of a multi-tenant database must have one or more tenant identifier columns so that the data from any given tenant can be selectively retrieved. Further, the schema might require a few tables or columns that are used by only a subset of tenants. However, static code and reference data is stored only once and is shared by all tenants.
Lower cost
In general, multi-tenant databases have the lowest per-tenant cost. Resource costs for a single database are lower than for an equivalently sized elastic pool. In addition, for scenarios where tenants need only limited storage, potentially millions of tenants could be stored in a single database. No elastic pool can contain millions of databases. However, a solution containing 1000 databases per pool, with 1000 pools, could reach the scale of millions at the risk of becoming unwieldy to manage.
Hybrid shared multi-tenant database model
In the hybrid model, all databases have the tenant identifier in their schema. The databases are all capable of storing more than one tenant, and the databases can be shared. So in the schema sense, they are all multi-tenant databases. Yet in practice some of these databases contain only one tenant. Regardless, the quantity of tenants stored in a given database has no effect on the database schema
In this hybrid model, the single-tenant databases for subscriber tenants can be placed in resource pools to reduce database costs per tenant. This is also done in the database-per-tenant model.
Data Intelligence Through Serverless Application
You should especially consider using a serverless provider if you have a small hotel running business that you need hosted. However, if your application is more complex, a serverless architecture can still be beneficial, but you will need to architect your application very differently. This may not be feasible if you have an existing application. It may make more sense to migrate small pieces of the application into serverless functions over time.
A massively simplified view off the serverless architecture can be as below:
-
The authentication logic is deleted in the original application and is replaced with a third-party BaaS service (e.g., Auth0.)
-
Using another example of BaaS, the client is allowed to direct access to a subset of the database (for product listings), which itself is fully hosted by a third party (e.g., Google Firebase.) A different security profile is created for the client accessing the database in this way than for server resources that access the database.
-
These previous two points imply a very important third: some logic that was in the Pet Store server is now within the client—e.g., keeping track of a user session, understanding the UX structure of the application, reading from a database and translating that into a usable view, etc. The client is well on its way to becoming a single page application.
-
If we choose to use AWS Lambda as our FaaS platform we can port the search code from the original Pet Store server to the new Pet Store Search function without a complete rewrite, since Lambda supports Java and Javascript—our original implementation languages.
-
Finally, “purchase” functionality can be replaced with another separate FaaS function, choosing to keep it on the server side for security reasons, rather than reimplement it in the client. It too is fronted by an API gateway. Breaking up different logical requirements into separately deployed components is a very common approach when using FaaS.
Invest Your Resources in Business Data Intelligence
To survive in this highly competitive environment, hotels are on a verge to snatch opportunities available for performance optimization. The data on its own can never make sense to the business. You must know how to use the data in a creative way.
With business data intelligence tools and techniques as elaborated above, you can reduce a lot of manual labor by way of gathering the smallest nuggets of information. Getting a broader view of what all is going on, we can foretell several things, start from our own expenses on supplies and electricity, view annual yields and so much more. Shift your hotel business operations today with a data-driven approach to practice a viable decision making process.




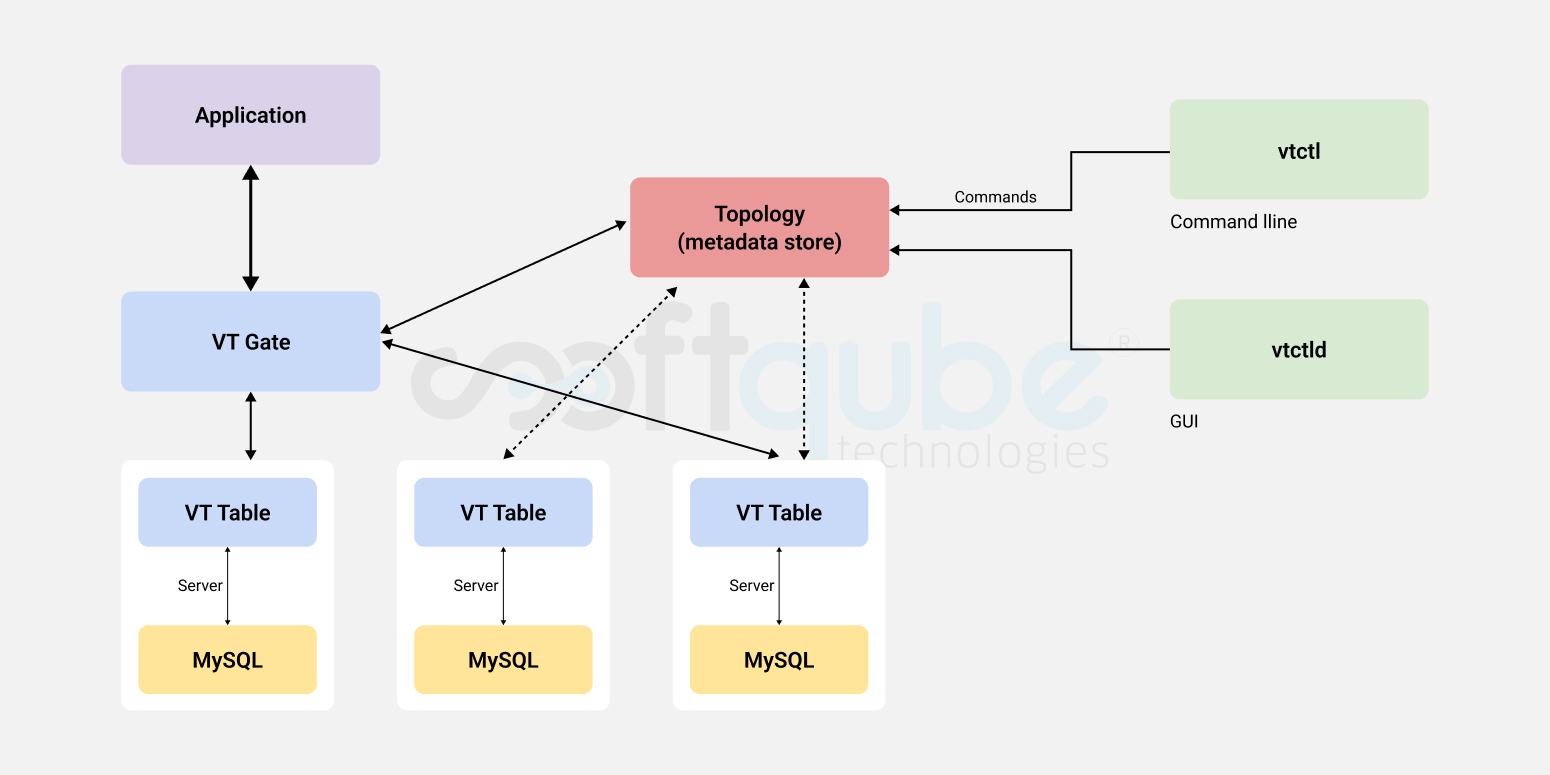
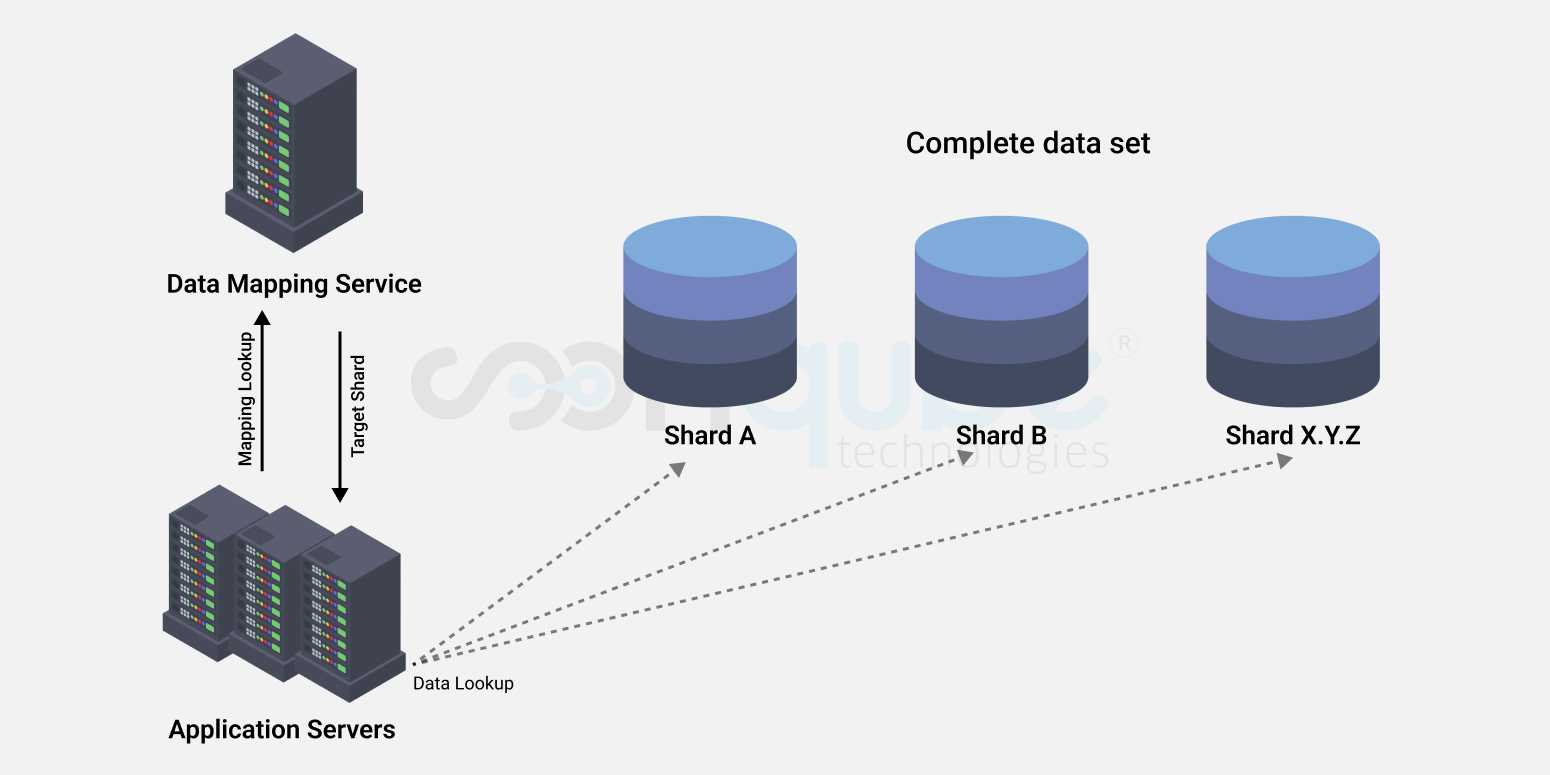

 Batch processing
Batch processing
 We can say different data is created at different times and there are times when most of the times the data is unequal or inconsistent. Further, different departments may also provide different data and managing these various data becomes a challenging task for organizations at times. Data is transferred through a complete cycle and it possesses a great value to the enterprise and selecting the best tool that maintains its value is of prime importance.
We can say different data is created at different times and there are times when most of the times the data is unequal or inconsistent. Further, different departments may also provide different data and managing these various data becomes a challenging task for organizations at times. Data is transferred through a complete cycle and it possesses a great value to the enterprise and selecting the best tool that maintains its value is of prime importance. So, now we can say that horizontal or row based databases can be used as transaction stores for operations, unorganized or half organized data which needs search style access, vertical stores for data analysis or a separate hard disk or device with more space that is used to drive business intelligence. And some of the highly abridged data storage devices are using for storing big data logs, front end that offers the reporting capabilities.
So, now we can say that horizontal or row based databases can be used as transaction stores for operations, unorganized or half organized data which needs search style access, vertical stores for data analysis or a separate hard disk or device with more space that is used to drive business intelligence. And some of the highly abridged data storage devices are using for storing big data logs, front end that offers the reporting capabilities.